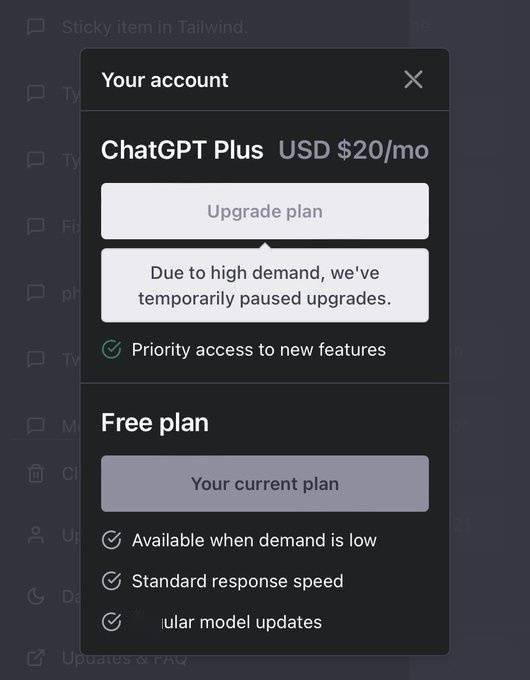
人工智能(AI)是今年科技行业最热门的事物,不过发展似乎进入了瓶颈期,研究发现,OpenAI的ChatGPT发布的最新模型GPT-4,在某些问题上的表现,竟比在3月时还要来得差,其中在回答基础数学问题的正确率,更是从98%下降到只剩2%。
根据斯坦福大学的1项研究发现,ChatGPT在执行某些任务的能力存在剧烈波动,该研究调查了GPT-3.5和GPT-4这2个模型,其中GPT-4在解决基础数学问题上存在明显变化。
研究人员发现,GPT-4在3月被问到17077是否为质数的问题时,回答正确率来到97.6%,不过到了6月,同样问题的回答正确率掉到只剩2.4%。 与此同时,GPT-3.5的状况完全相反,3月时对同一问题的正确率仅为7.4%,6月时则来到86.8%。

当研究人员要求ChatGPT写code或是进行视觉推理测试时,也出现了类似的不同结果。 3月和6月、以及2个模型的巨大差异,不仅反映出了模型在执行特定任务的准确性,也反映了模型在某一方面的变化,对其他部份产生了不可预测的影响。
史丹佛大学计算机科学教授James Zuo表示,当我们调整大型语言模型,以提高其在某些任务上的性能时,实际上可能会产生很多意想不到的后果,这实际上可能会损害该模型在其他任务上的性能。
James Zuo表示,模型该如何回答问题,存在各种有趣的相关依赖性,这可能导致了我们观察到的一些恶化的行为。
由于GPT-4没有开源,James Zuo表示,因此我们也不知道模型本身、神经架构或是训练数据哪个环节,产生了怎么样的变化。